설치된 rpm 패키지가 잇는지 확인해야 겠지요
rpm -qa | grep <패키지명>
rpm --erase `rpm -qa | grep <패키지명>
rpm --erase --noscripts `rpm -qa | grep <패키지명>
위 과정은 <패키지명>로 시작되는 패키지를 찾아 삭제 하는 명령이다.
설치된 rpm 패키지가 잇는지 확인해야 겠지요
rpm -qa | grep <패키지명>
rpm --erase `rpm -qa | grep <패키지명>
rpm --erase --noscripts `rpm -qa | grep <패키지명>
위 과정은 <패키지명>로 시작되는 패키지를 찾아 삭제 하는 명령이다.
우선 리눅스 OR 페도라를 설치하면서 필요없을 것 같아서 FTP서버를 설치 하지 않았다고 하자.그럼 설치를 새로 해주고 설정등을 잡아주고 FTP서버를 기동시켜야 한다.그리고 설치는 했으나 사용을 하지 않는다고 재워 놓았다면
#rpm -qa |grep proftpd 를 입력하여 패키지 파일을 검색해 보고 있으면
#rpm -ivh 패키지파일이름 을 입력하여 설치를 하자.
없으면 rpm 파일이라던지 다른 소스 파일을 다운받아서 설치 하도록하자.소스파일 다운 받을 수 있게 친절하게 알려준 블로그나 지식자료들이 오래되어서 그 서버들이 제대로 동작을 안하는 데가 많았다.
본좌는 돌다 돌다 헤메다 헤메다 여기서 다운받다.. http://www.proftpd.org에 접속하면 아래와 같은 그림이 나온다.빨간색으로 표시 해놓은 [gz] 파일을 클릭하여 다운 받도록 한다.
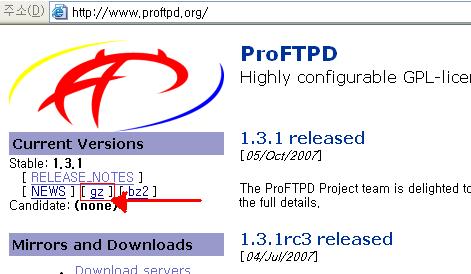
(위의 사이트에서 빨간색으로 표시된 부분을 클릭하면 알아서 다운로드 창이 뜬다.그러나 약간 서버가 불안해서 안될때도 있다)
[bz2]파일을 선호하면 그것을 다운받아도 된다.개인적인 취향이니 그건 각자가 알아서 선택하도록 한다. 파일을 다운받아 놓을 폴더로 이동한다.
# cd /usr/local/src/ <-- 난 요기다 다운받았다.
각자 소스파일을 받아서 활용하는 곳으로 받아서 풀어주길 바란다.이것도 저것도 모르는 초보라면 그냥 따라 해주실 바란다.그리고 압축을 풀어야 하는데 다운 받은 폴더로 이동을 해서 아래와 같은 명령어를 입력해주도록 한다.
# tar xvfz proftpd-1.3.1.tar.gz
(P.S:
압축을 푸는 진행과정이 모니터에 주루룩 올라가면서 나오게 된다.그리고 여기서 TIP하나! Tab 키를 사용하게 되면 긴 소스파일 이름을 다 입력하지 않아도 되므로 자주 활용하도록하자.사용법은 위의 proftpd-1.3.1.tar.gz 을 입력할려고 한다고 하자.그럼 앞의 명령어들을 다 이렇게 다 써놓고
# tar xvfz pro 까지만 입력하고 tab키를 누르게 되면 나머지 소스 파일명이 알아서 입력이 된다.단 주의 사항은 같은 이니셜이 있다면 입력되지 않고 같은 이니셜을 가지고 있는 파일명들이 화면으로 보여준다.그렇게 되면prof 까지 쓰고 다시 tab키를 누르게 되면 나머지 부분이 자동으로 입력되게 된다. )
자 이제 압축을 다 풀었다면 압축을 풀어 놓은 proftpd 폴더로 이동합니다. 위의 경로에 다운 받으셔서 압축을 풀으셨다면 proftp파일의 경로는 아래와 같을 것이다.
# cd /usr/local/src/proftpd-1.3.1 <-- 해당경로로 이동
해당경로에서 아래와 같이 쓰자.
# ./configure \
--prefix=/usr/local/proftpd \
--enable-autoshadow
그리고 설정이 잡히면
make && make install
명령을 순서대로 차례 차례 내리도록 하자.
그리고 설정을 잡아 주셔야 하네~~.. 설정을 잡기위해서 해당 설정파일(proftpd.conf) 을 열어 주자.
# vim /usr/local/proftpd/etc/proftpd.conf
(PS:
여기서부턴 http://blog.naver.com/ljhamway/150025243686 의 약속의 땅님의 블로그 글을 참고 수정하여 내용을 적었습니다.)
------------------------------------------------------------------------------------------
proftpd.conf 설정 내용 확인
------------------------------------------------------------------------------------------
# This is a basic ProFTPD configuration file (rename it to
# 'proftpd.conf' for actual use. It establishes a single server
# and a single anonymous login. It assumes that you have a user/group
# "nobody" and "ftp" for normal operation and anon.
ServerName "ProFTPD Default Installation"
ServerType standalone
-----부연설명----------------------------------------------------------------
보통 ServerType 은 standalone방식과 inetd방식이 있습니다.
ftp나 대형서버같은 경우는 항상 ftp를 열어둬야 겠지만, 저같이 스터디용~서버에 ftp사용자를 막아놓고 일부분만 허용하시는
분은 xinetd로 사용하는것이 서버에 과부하를 줄일수 있는 한가지 방법이겠죠
standalone로 사용하실분은 특별히 다른 기능을 넣을 필요는 없습니다. 유저와 그룹설정만 바꿔주시고 사용하시면 되고
inetd으로 사용하시려는 분들은 좀 복잡한데..
이방식은 따로 xinetd를 설치하셔야 합니다 (페도라 코어4의 기준에는 xinetd가 설치가 되어있지를 않습니다. ) 설치하시기전에
혹시나 설치가 되어 있는지 확인은 하셔야죠^^
RPM으로 설치가 되어 있다면..
RPM -qa | grep xinetd 로 검색하시면 뭔가 나올거에요 안나오면 RPM으로는 설치 안된거고
find /-name xinetd.* 하셔서 관련 파일이 있으면 아마도 설치가 되어 있을것입니다.
설치가 안되있는것을 확인 하셨다면... 그냥 yum으로 설치하시면 되요
yum install xinetd
설치가되셨다면 그다음에는 ....
xinetd가 기동시 불러들이는 폴더는 /etc/xinetd.d/폴더 입니다 일단 이 폴더로 이동을 해봅시다.
그후 proftp가 xinetd로 불려질수 있겠끔 아래의 내용으로 파일을 하나 생성하셔야 합니다
ervice ftp
{
flags = REUSE
socket_type = stream
instances = 50
wait = no
user = root
server = /usr/sbin/proftpd
bind = <the-ip-you-wish-to-bind-to>
log_on_success = HOST PID
log_on_failure = HOST RECORD
}
(PS:
이 부분에서 서버용으로 쓸려고 했기때문에 그래픽으로 보여주는 x-windowd를 설치하지 않아서 standalone방식으로 사용을 하게 되었다.기회가 될 때 이부분은 다시 수정해서 쓰도록 하겠다.부족한 부분과 필요한 부분은 따로 자료를 검색해 봐주길 바란다.)
----------------------------------------------------------------------------------
proftpd.conf 내용 계속 ......
-----------------------------------------------------------------------------------
DefaultServer on
# Port 21 is the standard FTP port.
Port 21
# Umask 022 is a good standard umask to prevent new dirs and files
# from being group and world writable.
Umask 022
# To prevent DoS attacks, set the maximum number of child processes
# to 30. If you need to allow more than 30 concurrent connections
# at once, simply increase this value. Note that this ONLY works
# in standalone mode, in inetd mode you should use an inetd server
# that allows you to limit maximum number of processes per service
# (such as xinetd)
MaxInstances 30
# Set the user and group that the server normally runs at.
User nobody
Group nogroup <--이렇게 되어 있으면 nobody로 바꾸세요
# To cause every FTP user to be "jailed" (chrooted) into their home
# directory, uncomment this line.
#DefaultRoot ~
DefaultRoot ~ !root (root를 제외한 접속자들이 상위로 기어올라 가지 못하게 하는 부분입니다)
# Normally, we want files to be overwriteable.
<Directory /*>
AllowOverwrite on
</Directory>
# A basic anonymous configuration, no upload directories.
<Anonymous ~ftp>
User ftp
Group ftp
# We want clients to be able to login with "anonymous" as well as "ftp"
UserAlias anonymous ftp
# Limit the maximum number of anonymous logins
MaxClients 10
# We want 'welcome.msg' displayed at login, and '.message' displayed
# in each newly chdired directory.
DisplayLogin welcome.msg
DisplayFirstChdir .message
# Limit WRITE everywhere in the anonymous chroot
<Limit WRITE>
DenyAll
</Limit>
</Anonymous>
//설정내용 끝 (자세한 설정은 다른 분들것도 참조하세요)----------------------------
자 이제 설정을 마쳤으니 데몬을 돌려서 우리가 원한 FTP가 동작하는 것을 확인해봐야 하지 않을까?
# /usr/local/proftpd/sbin/proftpd
(xinetd 로 운영하시면 /usr/local/proftpd/sbin/proftpd start)
- warning: unable to determine IP address of 'localhost.localdomain'
(OR warning: unable to determine IP address of '자신의 호스트네임')
- error: no valid servers configured
- Fatal: error processing configuration file '/usr/local/proftpd/etc/proftpd.conf'
그럼 부분 위와 같은 드러운 에러 내용을 만나게 돈다.여기 저기 자료를 찾던중 약속의 땅님의 블로그에서 실마리를 찾게 되었다.아래와 같이 명령어를 입력하고 엔터를 치게되면
# vim /etc/hosts
-----------------------------------------------
hosts 설정
-----------------------------------------------
# Do not remove the following line, or various programs
# that require network functionality will fail.
::1 localhost.localdomain localhost
-----------------------------------------------
설정 마침
-----------------------------------------------
여기서
::1 localhost.localdomain localhost <--- 이부분을 아래와 같이 수정
127.0.0.1 localhost.localdomain localhost
주의하실 부분은 도메인을 이용해서 로그인하는 분들께는 추가를 해야할 부분이 있다.
여기서 hostname이 아닌 IP를 이용해서 접속하게 되는데 무슨 소리냐 하면 아래 그림을 보면 리눅스에 접속했을때 사용자@뒤에 붙는것 문자열 중에 IP주소로 쓰여져서 나오는 경우가 있고 아니면 설치를 할때 설정 환경 부분에서 정해준 각자의 호스트 네임으로 문자열이 보여지게 된다.

(사용자 root@ 뒤에 있는 빨간색으로 쳐져있는게 HOSTNAME 이다.)
IP주소를 사용 하는 분들은 위의 내용처럼 입력을 하게 되면 에러메세지가 나오지 않고 FTP를 기동 시킬수 있고 HOSTNAME를 사용하는사람들은 아래와 같이 수정하여서 FTP를 기동시키자.
예를 들어 호스트 네임이 good 이고 IP주소가 999.999.999.999 이고 도메인이 www.good.com 이라고 하면
-----------------------------------------------
::1 localhost.localdomain localhost <--- 이부분을 아래와 같이 수정해 주자.(당연히 이 부분은 지우고 아래의 두 줄만 입력하자.)
-----------------------------------------------
127.0.0.1 localhost.localdomain localhost
999.999.999.999 www.good.com good
라고 수정을 하고 다시 proftpd 를 실행시키면 에러 메세지가 뜨지 않는다. 위 명령어의 의미는
IP 999.999.999.999 와 도메인 www.good.com 과 HOSTNAME good 는 같다라는 명령을 내린것이다.위에서 에러창에 뜬 hostname의 주소를 정해준 거라 생각하면 이해가 쉽게 되겠다.그리고 예를 들어서 good 를 썼으니 오해 없길 바란다.
#/usr/local/proftpd/sbin/proftpd 이렇게 proftp를 실행후 FTP가 돌아가는지 확인할려면
#ps -aux | grep proftpd 라고 입력을 하면 아래와 같은 화면을 볼 수 있다.
nobody 23595 0.0 0.4 2465______________________________ proftpd:(accepting connections)
root 22343 0.0 0.6 3009______________________________ grep proftpd
라는 화면을 볼 수 있다. 보안상 빨간 언더바를 쳐서 나머지 부분을 표시하였다.그러니 황당해 하지말고 nobody 와 root 가 뜨면 성공한 것이다.그리고 우리는 리눅스를 설치할 때 FTP서버를 안 깔았다는 전제하에서 시작한 것이므로 리눅스 명령창에서
#setup 을 입력하고 그 다음에 나오는 설정 창에서
Firewall configuration 메뉴로 들어가서 커스터 마이즈 메뉴 아래에 [ ] FTP라고 되어 있는 부분을 [ * ] FTP 로 선택해 주자. FTP를 사용하겠다는 인증을 받는 것이므로 중요하다.그리고 나서 클라이언트 프로그램인 LeechFTP 등을 사용하여 쉽게 자료를 올리고 다운 받아 보도록하자.LeechFTP에 대한 사용법은 다음 시간에 다시 하도록 하겠다.
급하면 웹을 검색해서 찾아보도록 한다.설정하기가 아주 쉽다.서버프로그램인 proftpd 와 클라이언트 프로그램인 LeechFTP를 잘 구별해서 생각하도록 하자.서버프로그램이 없으면 클라이언트 프로그램을 설치해봐도 아무런 소용이 없다.그리고 FTP관련 기타 명령어는 다음과 같다.
#killall proftpd //프로세스 죽이기(종료)
# /usr/local/proftpd/sbin/proftpd //ProFTP 데몬 띄우기
(P.S:
proftp를 죽인후 다시 재생할 땐 안 될 수도 있다. 왜 그러냐면Ftp를 정시키시면 /etc/shutmsg 파일이 생성된다. 이 파일을 지워야 재가동 할 수 있으니 찾아서 지우고 다시 실행하도록 한다.)
/etc/sysconfig/i18n 내용에 아래내용을 집어넣는다.
#> Vi /etc/sysconfig/i18n
LANG="ko_KR.eucKR"
SUPPORTED="en_US.iso885915:en_US:en:ko_KR.eucKR:ko_KR:ko"
SYSFONT="lat0-sun16"
SYSFONTACM="iso15"
저장후 빠져나와 설정을 적용시킨다.
source /etc/sysconfig/i18n
저장후 빠져나와 설정을 적용시킨다.
source /etc/sysconfig/i18n
log4sql을 사용하면 I,U,D,S 쿼리문과 쿼리 수행시간, parameter까지 확인을 할 수 있습니다.
사용방법은 간단합니다.
라이브러리만 추가해준후 driver class만 변경해주면 됩니다.
보다 자세한 사용법 및 jar파일은 아래 URL에서 확인하시면 됩니다.
out 객체는 JSP 페이지의 결과를 웹 브라우저에 전송해 주는 출력 스트림을 나타내며 JSP페이지가 웹 브라우저에게 보내는 모든 정보는 out객체로 통해서 전달이 된다.
out객체는 java.io.Writer 클래스를 상송 받은 javax.servlet.jsp.JspWriter클래스 타입의 객체이며 out객체로 사용한다.
주로 많이 사용되는 메소드는 웹 브라우저에 출력을 하기 위한 println() 메소드이다.
out 내부 객체의 메소드
boolean isAutoFlush() 출력버퍼가 다 채워진 경우에 자동으로 flush했을 경우는 true를 리턴, 그렇지 않은 경우는 false 를 리턴한다.
int getBufferSize() 출력 버퍼의 전체의 크기를 바이트 단위로 리턴한다.
int getRemaining() 출력 버퍼의 남은 양을 바이트 단위로 리턴한다.
void clearBuffer() 현재 출력 버퍼에 저장된 내용을 취소한다.(비운다.)
String println(string) 현재 출력 버퍼에 저장된 내용르 웹 브라우저로 전송하고 버퍼를 비운다.
void close() 출력 버퍼의 내용을 flush하고 스트림을 닫는다.
|
리턴타입 |
메소드명 |
설명 |
| 없음 | clear() |
출력버퍼에 저장된 내용을 버림. 비었을 경우 예외발생 |
| 없음 | clearBuffer() |
clear()메소드와 같은 역할이지만, 버퍼가 빈경우에도 예외발생않고 현재 버퍼를 비움 |
| 없음 | flush() |
현재 버퍼에 저장된 내용을 클라이언트로 전송하고 버퍼를 비움. |
| 없음 | close() |
출력 버퍼를 클라이언트로 전송하고 출력스트림 종료 |
| boolean | isAutoFlush() | page지시어의 autoFlush속성으로 지정된 값을 리턴 |
| int | getBufferSize() | 출력 버퍼의 크기를 바이트 단위 |
| int | getRemaining() | 출력 버퍼의 남은 양 |
| 없음 | print(String str ) | 출력 스트림으로 str 문자열 출력 |
tomcat/common/lib/ 아래에
ojdbc14라이브러리 추가
아울러 jdk1.5/lib 안에도 꼭 있어야 함..
jdk1.5/jre/lib/ext 안에는 있으나 마나이다..
==========================================
위 작업 끝난 다음에...도 jdbc 드라이버가 인식이 안됫었는데 알보고니 철자가 틀려서 그런거였다;;
ㅠㅠ;;;
'oracle.jdbc.dirver.OracleDriver' 로 써 있었던 것이였다 =>'oracle.jdbc.driver.OracleDriver' 로 바꿔야 햇는데;;
org.apache.tomcat.dbcp.dbcp.SQLNestedException: Cannot load JDBC driver class 'oracle.jdbc.driver.OracleDriver'
at org.apache.tomcat.dbcp.dbcp.BasicDataSource.createDataSource(BasicDataSource.java:766)
at org.apache.tomcat.dbcp.dbcp.BasicDataSource.getConnection(BasicDataSource.java:540)
at org.apache.jsp.index_jsp._jspService(index_jsp.java:62)
at org.apache.jasper.runtime.HttpJspBase.service(HttpJspBase.java:98)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:803)
at org.apache.jasper.servlet.JspServletWrapper.service(JspServletWrapper.java:328)
at org.apache.jasper.servlet.JspServlet.serviceJspFile(JspServlet.java:315)
at org.apache.jasper.servlet.JspServlet.service(JspServlet.java:265)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:803)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:269)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:188)
at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:210)
at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:174)
at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:127)
at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:117)
at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:108)
at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:151)
at org.apache.coyote.http11.Http11Processor.process(Http11Processor.java:870)
at org.apache.coyote.http11.Http11BaseProtocol$Http11ConnectionHandler.processConnection(Http11BaseProtocol.java:665)
at org.apache.tomcat.util.net.PoolTcpEndpoint.processSocket(PoolTcpEndpoint.java:528)
at org.apache.tomcat.util.net.LeaderFollowerWorkerThread.runIt(LeaderFollowerWorkerThread.java:81)
at org.apache.tomcat.util.threads.ThreadPool$ControlRunnable.run(ThreadPool.java:685)
at java.lang.Thread.run(Unknown Source)
Caused by: java.lang.ClassNotFoundException: oracle.jdbc.driver.OracleDriver
at java.net.URLClassLoader$1.run(Unknown Source)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(Unknown Source)
at java.lang.ClassLoader.loadClass(Unknown Source)
at java.lang.ClassLoader.loadClass(Unknown Source)
at java.lang.ClassLoader.loadClassInternal(Unknown Source)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Unknown Source)
at org.apache.tomcat.dbcp.dbcp.BasicDataSource.createDataSource(BasicDataSource.java:760)
... 22 more
Logging Messages from Servlets and JSPs
웹 어플리케이션에서 로그를 기록하는 법은 크게 2가지가 있습니다.
하나는 ServletContext.log() 를 이용하는 것이고 다른 하나는 Log4j 를 이용하는 것입니다. 먼저 ServletContext.log()를 사용해서 로그를 남기는 방법을 보겠습니다.
import javax.servlet.*;
import javax.servlet.http.*;
public class MyLog extends HttpServlet {
public void goGet( HttpServletRequest request, HttpServeltResponse response ) throws SevletException, java.io.IOException {
ServletContext context = getServletContext();
context.log("에러가 발생했습니다.");
context.log("에러가 발생했습니다.",new IllegalStateException("잘못된 파라메터입니다."));
}
}
log 메서드는 2개가 있는데 하나는 String 변수만 받고 다른 하나는 String와 Throwable을 받습니다.
Log4j 를 사용하는 방법은 좀더 자세히 보겠습니다. 요것은 아주 유용하기 때문에 자세히 봐야 합니다.^^
먼저 Log4j를 셋업하는 방법부터 보겠습니다. 일단 셋업을 하기전에 다운받아 설치를 해야합니다.
http://jakarta.apache.org/log4j/docs/download.html
여기서 다운받아 톰켓의 WEB-INF/lib 에 가져다 놓습니다. 압축을 풀면 jakarta-log4j-1.2.8 파일이 나옵니다. 파일이름은 버젼마다 틀려집니다. 참고하세요. 압축을 풀고 WEB-INF/lib 에다가 가져다 놓았으면 properties 파일을 만들어야 합니다. 이는 단순히 text파일로 키,값으로 이루어져 로그파일에 대한 각종 정보들을 담아둡니다. 이 프로퍼티 파일로 log4j를 서블릿에서 사용하기 위해선 2개의 패키지를 import 해야 합니다.
import org.apache.log4j.Logger;
import org.apache.log4j.PropertyCofigurator;
하지만 이 프로퍼티 파일을 이용하지 않고 싶을때는 log4j에서 지원하는 default configurator를 이용할 수 있습니다. 이때는 PropertyCofigurator 대신 BasicConfigurator를 임포트 합니다. 사용법은 약간 다르니 주의하세요.
import org.apache.log4j.Logger;
import org.apache.log4j.BasicConfigurator;
import javax.servlet.*;
import javax.servlet.http.*;
public class LoggerDefaultConfig extends HttpServelt {
private Logger log = null;
public void init(){
log = Logger.getRootLogger();
BasicConfigurator.configurator();
}
public void goGet( HttpSevletRequest req, HttpServletResponse res ) throws ServletException, java.io.IOException {
log.debug("디버깅 메시지입니다.");
log.info("정보 메시지입니다.");
}
}
다음은 configuration file 을 이용한 로그 사용법을 보겠습니다.
먼저 log4j.properties 파일을 만들고 web-inf/classes 폴더에다가 넣습니다. 그리고 사용하고자 하는 서블릿에다가 org.apache.log4j.Logger 를 import를 합니다. 그런다음 정적 메소드인 Logger.getRootLogger() 를 사용하여 레퍼런스를 얻어와서 로그를 남김니다.
이 로그파일에는 org.apache.log4j.ConsoleAppender 타입의 이름을 붙입니다. 여기서는 hans로 정하겠습니다.
log4j.rootLogger=DEBUG, hans
log4j.appender.hans=org.apache.log4j.ConsoleAppender
log4j.appender.hans.layout=org.apache.log4j.SimpleLayout
BasicConfigurator.configure( ) 이게 호출되지 않으면 자동으로 web-inf/classes 에서 log4j.properties 파일을 찾아 설정하게 됩니다.
log4j.rootLogger=DEBUG, cons
log4j.logger.com.jspservletcookbook=, myAppender
#the root logger's appender
log4j.appender.cons=org.apache.log4j.ConsoleAppender
#the com.jspservletcookbook logger's appender log4j.appender.myAppender=org.apache.log4j.RollingFileAppender
log4j.appender.myAppender.File=h:/home/example.log
log4j.appender.myAppender.MaxBackupIndex=1
log4j.appender.myAppender.MaxFileSize=1MB
#the root logger's layout
log4j.appender.cons.layout=org.apache.log4j.SimpleLayout
#the com.jspservletcookbook logger's layout
log4j.appender.myAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.myAppender.layout.ConversionPattern=%-5p
Logger:%c{1} Date: %d{ISO8601} - %m%n
위 코드는 myAppender라는 이름으로 rootLogger를 상속하여 다양한 로그를 남기는 법을 보여줍니다.
the log4j Javadoc page: http://jakarta.apache.org/log4j/docs/api/index.html [출처] log 남기기 ( with log4j )|작성자 달콤인생
the log4j project documentation page: http://jakarta.apache.org/log4j/docs/documentation.html
개발자 생존 가이드 발표하기 전 자바서비스넷의 이원영님이 추천해주셨던 내용이기도 했습니다. http://www.inter-sections.net/2007/11/13/how-to-recognise-a-good-programmer/
6가지 요소를 얘기합니다. 물론 여러 요소들이 많겠지만, 6가지 소양은 다음과 같습니다.
#1 : Passion
#2 : Self-teaching and love of learning
#3 : Intelligence
#4 : Hidden experience
#5 : Variety of technologies
#6 : Formal qualifications
물론 변명의 여지도 Disclaimer에 남겨놓았습니다. 저 조건을 만족하는 것이 모두 좋은 프로그래머는 아니고, 또한 일부 조건에 맞는 형편없는 프로그래머도 있다고. 하지만 비즈니스맨 입장에서 좋은 프로그래머는 알아놓을 필요가 있다고 얘기합니다.
하단에 있는 긍정적인 지표와 부정적인 지표들로 내용을 마무리짓습니다.
Positive indicators:
* Passionate about technology
* Programs as a hobby
* Will talk your ear off on a technical subject if encouraged
* Significant (and often numerous) personal side-projects over the years
* Learns new technologies on his/her own
* Opinionated about which technologies are better for various usages
* Very uncomfortable about the idea of working with a technology he doesn’t believe to be “right”
* Clearly smart, can have great conversations on a variety of topics
* Started programming long before university/work
* Has some hidden “icebergs”, large personal projects under the CV radar
* Knowledge of a large variety of unrelated technologies (may not be on CV)
Negative indicators:
* Programming is a day job
* Don’t really want to “talk shop”, even when encouraged to
* Learns new technologies in company-sponsored courses
* Happy to work with whatever technology you’ve picked, “all technologies are good”
* Doesn’t seem too smart
* Started programming at university
* All programming experience is on the CV
* Focused mainly on one or two technology stacks (e.g. everything to do with developing a java application), with no experience outside of it
사람을 뽑는 입장이라면 자신과 같은 사람을 뽑을까요? 대답이 "Yes"라면 이제 비즈니스맨을 잘 만나는 일만 남았군요. 제리 맥과이어 같은 사람말이죠.
6. 입력값 수집 [출처] Struts1 VS Struts2|작성자 슬레이어
스트럿츠1은 사용자의 입력값을 받기 위해 ActionForm 오브젝트를 사용합니다. 그리고 모든 ActionForm들은 프레임웍에 의존적인 기반 클래스를 extend 하도록 되어 있습니다. JavaBean이 ActionForm으로 사용될 수 없기 때문에 개발자들은 입력값을 받기 위해 과다한 클래스들을 생성해야 합니다.
그러나 스트럿츠2는 Action클래스의 프러퍼티들(프레임웍에 독립적인 입력 프러퍼티로서)을 사용함으로써 추가적인 입력값 처리 관련 오브젝트들의 필요성을 제거했고 그리하여 과다하게 클래스가 생성되는것을 방지합니다. 추가적으로 스트럿츠2에서 Action클래스의 프러퍼티들은 웹페이지 상에서 태그라이브러리로 접근이 됩니다. 스트럿츠2는 POJO 폼오브젝트와 POJO Action을 지원할 뿐만 아니라 ActionForm형태의 사용도 지원합니다. 비즈니스 오브젝트나 도메인 오브젝트와 같은 타입들 역시 입력/출력값 관련 오브젝트로 사용이 가능합니다.
7. 표현식(Expression Language)
스트럿츠1은 JSTL과 통합되기 때문이 보통 JSTL을 EL로 사용합니다. 스트럿츠1은 기본적인 수준의 오브젝트내의 값에 대한 처리/순회를 지원하지만 상대적으로 컬렉션과 인덱스가 지정된 프러퍼티에 대한 지원이 약합니다. 스트럿츠2 또한 JSTL을 사용합니다만 보다 강력하고 유연한 Expression Langugae인 OGNL(Object Graph Notation Language)을 지원합니다.
8. 값을 뷰에 연결하기
뷰의 관점에서 보면 스트럿츠1은 오브젝트(Model에서 처리된 결과값을 담은)을 페이지 컨텍스트에 바인딩하기 위해 표준적인 JSP 메커니즘을 사용합니다.
하지만 스트럿츠2는 "Value Stack" 이란 기술을 사용하므로 View와 View가 렌더링할 오브젝트를 연결해놓지 않고도 태그라이브러리를 사용하여 값에 접근할 수 있습니다. Value Stack를 사용하여 값을 프로퍼티명을 사용하지만 그 타입이 다를 수도 있는 항목들을 가진 View들의 경우 해당 View를 재사용할 수 있습니다.
9. 형변환
보통 스트럿츠1에 있어 ActionForm의 프러퍼티값들은 모두 String형입니다. 스트럿츠1은 형변환시에 Commons-Beanutils를 사용합니다. 이런 타입컨버터들은 클래스당 하나씩 할당되고 인스턴트당 하나씩으로 설정할 수 없습니다.
하지만 스트럿츠2는 형변환에 OGNL을 사용합니다. OGNL의 구조는 기본적이고 공통적인 오브젝트의 타입과 프리미티브 타입에 대한 컨버터를 포함하고 있습니다.
10. Action의 실행에 대한 제어
스트럿츠1은 각 모듈당 별개의 RequestProcessors(라이프사이클)을 지원하지만 동일한 모듈내의 모든 Action들은 동일한 라이프사이클을 공유해야하만 합니다. 그러나 스트럿츠2는 Interceptor Stack을 사용하여 Action당 다른 라이프사이클을 가질 수 있도록 지원하고 있습니다. 필요하다면 커스텀 스택도 생성/사용할 수 있습니다.
[출처] [EJB] EJB 는 왜 사용하는가 ?|작성자 슬레이어
처음 Struts 2 Framework 을 설치하고 환경설정하는 내용입니다. Struts 2 Framework 으로 웹 어플리케이션을 작성하기 위해서는 기본 선수 지식이 필요합니다. 아래의 기술들을 어느정도 알고 있어야 Struts 2 Framework 으로 웹 어플리케이션 작성이 쉽습니다.
국내 자바 개발자들이 Struts 2 Framework 를 익히고, 개발하는데 서로의 노하우를 공유할 수 있도록 게시판을 만들어 질답 및 팁을 여러사람이 볼 수 있도록 하였습니다.
Apache Struts 2 Framework 를 다운로드 받기 위해서는 Apache Struts Download 싸이트로 가서 최신 버전을 다운로드 받습니다.
Struts 2 Framework 웹 어플리케이션을 작성하기 위한 설정을 살펴본다.
Struts 2 Framework 어플리케이션을 개발하기 위해서는 최소한 필요한 파일을 복사합니다. 그 목록은 아래에 나와 있습니다.
web.xml 파일에 Struts 2 Framework 을 연동하는 내용을 기술합니다. 아래의 내용과 같이 web.xml 을 구성합니다.
web.xml 에 FilterDispatcher 를 등록하여 request 가 발행하면 Struts 2 Framework 가 그 request 를 받도록 설정합니다.
<?xml version="1.0"?>
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd"><web-app>
<display-name>My Application</display-name>
<filter>
<filter-name>struts2</filter-name>
<filter-class>org.apache.struts2.dispatcher.FilterDispatcher</filter-class>
</filter>
<filter-mapping>
<filter-name>struts2</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
</web-app>
Struts 에서 작성한 어플리케이션이 정상적인 동작을 하기 위해서 필요한 환경설정 내용을 포함하고 있습니다.
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configuration 2.0//EN"
"http://struts.apache.org/dtds/struts-2.0.dtd"><struts><!-- Configuration for the default package. -->
<package name="default" extends="struts-default">
...
</package>
</struts>
2. Hello World
Struts 2 Framework 를 사용한 Hello World 웹 어플리케이션을 작성해봅니다. 웹페이지에서 Request 를 발생시키고, 서버에서 해당 Request 를 받은 다음, Hello World 문자열을 다시 보내서, 브라우저에서 Hello World 문자열을 나타냅니다.
원문에서는 간단한 소스와 환경설정하는 방법이 나와 있지만, 한글화를 하면서 Eclipse 를 사용하여, 각 단계별로 이미지를 포함하였습니다.
최신 Eclipse 버전인 Eclipse Europa JEE 버전을 사용하여 HelloWorld Web Application 을 작성합니다.
우선 Workspace 를 생성합니다.
File -> New -> Project 메뉴를 선택하고, Web -> Dynamic Web Project 를 선택합니다.
Project Name : Hello World 로 입력합니다.
Dynamic Web Project 를 생성한 후에 실행할 서버(runtime) 을 지정해야 합니다. 현재는 처음으로 프로젝트를 생성하였기에, 설정된 Target Runtime 이 없습니다.
Hello World 어플리케이션은 웹 어플리케이션이기 때문에, 가장 많이 사용되는 Tomcat 를 지정하여 실행을 하도록 합니다.
따라서 Tomcat 을 설치하고 난 후, 톰캣을 Target Runtime 으로 지정합니다.
New 버튼을 클릭하고, Apache -> Apache Tomcat 5.5 를 선택합니다.
그리고 Tomcat 이 설치된 디렉토리를 지정합니다.
Finish 버튼을 클릭하면 Target Runtime 이 위에서 설정한 Tomcat 으로 지정된 것을 확인할 수 있습니다.
Struts 2 Framework 을 사용하기 위해서는 위에서 설명한 필수 라이브러리를 포함시켜야 합니다.
Eclipse 에서 User Library 에 Struts 2 Framework 에서 사용되는 라이브러리를 추가합니다.
Struts 2 Framework 을 연동하여, Request 가 발생되면 Struts 2 로 처리가 되도록 web.xml 을 아래와 같이 수정합니다.
Request 가 발생되고, 그 결과를 화면에 보여질 JSP 파일을 추가합니다.
File -> New -> JSP 를 선택하고, HelloWorld.jsp 로 입력합니다.
그리고 아래와 같이 소스 코드를 입력합니다.
그리고 HelloWorld 클래스를 생성하고 아래와 같이 구현합니다.
File -> New -> Class 메뉴를 선택하고, Package : com.javamodeling.struts2, Name : HelloWorld 를 입력합니다.
Request 가 발생되고, 어느 Action 클래스가 Request 를 처리하고, 그에 따른 처리 결과에 따라서 JSP 파일로 Forwording 을 해야 합니다.
이러한 sturts 2 의 전체 환경설정을 struts.xml 에 정의를 합니다.
src -> new -> Other -> XML -> XML 을 선택하고, struts.xml 파일을 생성하고 아래와 같이 입력합니다.
배포하기 위해서는 Servers 탭에서 Add and Remove Projects 메뉴를 선택하고, HelloWorld 프로젝트를 추가합니다.
Server 를 실행하고, 주소창에 다음과 같이 입력하면 http://localhost:8080/HelloWorld/HelloWorld.action 아래와 같은 결과를 확인할 수 있습니다.
간단하게 Struts2 Framework 을 사용하여 HelloWorld 어플리케이션을 작성해 보았습니다.
Request 가 발생해서, 최종 Response 가 Browser 까지 전달되는 과정이 어떻게 되는지 살펴보겠습니다.
3. Using Tags
지금부터는 위에서 작성한 Hello World 어플리케이션에 추가로 기능을 덧붙이도록 하겠습니다. Hello World 는 실행하기 위해서 간단하게 설정만 하였지만, 지금 부터는 몇몇 기능을 추가하여 기본적인 어플리케이션을 만들어보겠습니다.
우선 웹 어플리케이션에서는 다른 페이지나 Request 를 발생할 수 있고, HyperLink 를 추가할 수 도 있습니다.
페이지에 동적으로 HTML 코드를 처리하기 위해서 많이 사용되고 있는 것이 Tag 이며, Struts 2 Framework 에서 사용되고 있는 몇 개의 Tag 를 살펴보겠습니다.
많이 사용되고 있는 기능중에 하나가 다른 페이지로 연결하는 Link 입니다. Welcome.jsp 파일을 추가하고, 아래와 같이 코딩합니다.
결과 페이지를 각 언어별로 볼 수 있도록 페이지 링크를 추가한 화면입니다. 각 언어별로 Resource Bundle 에서 값을 읽어서 결과를 처리하기 위함입니다.
위와 같이 처리하기 위해서 HelloWorld.jsp 파일을 아래와 같이 추가합니다.
위 Welcome.jsp 와 HelloWorld.jsp 에서 두가지의 Link 하는 방법을 나타내고 있습니다. HellWorld.jsp 에서 사용된 %{url} 은 <s:url> 태그에서 사용된 url 값을 그대로 사용하는 방법입니다.
<s:url> 이 사용된 방법은 위 예제에서 아래의 세가지 경우입니다.
만약 Welcom Action 이 실행된 후, 그 결과를 특정 페이지로 Forwarding 해야 합니다. Welcome Action 을 처리하기 위해서 struts.xml 에 아래 내용을 추가합니다.
<actjon> 태그에서 class 속성을 부여하지 않으면 Action 클래스를 수행하지 않고 직접 페이지로 Forwarding 합니다.
이렇게 Action 이름과 Forwarding 할 페이지 이름이 동일할 경우, 아래과 같이 wildcard mapping 을 사용하여 처리를 하면 훨씬 편리합니다.
아래와 같이 코딩해도 결과는 마찬가지로 나타납니다.
입력폼을 처리해야 하는 경우에, Struts 2 의 태그에서도 입력 폼을 위한 태그를 사용할 수 있습니다. 아래와 같이 간단하게 태그를 추가해보겠습니다.
Logon.jsp 파일을 생성하고, 아래와 같이 코딩합니다. Struts 2 태크가 HTML Form 형식에 맞게 rendering 을 해줍니다.
4. Coding Action
위에서 Tag 부분을 설명하면서 Login Form 을 완성하였습니다. 이번에는 Login Action 을 구현해 보겠습니다. Login Action 에서 비즈니스 로직이 수행되고 난후에 그 결과에 따라서 리턴하는 값이 달라지게 됩니다.
그리고 아래 URL 로 로그인 기능이 수행됩니다.
http: //localhost:8080/HelloWorld/Logon.action
Login.action 이 호출되면, User Name 과 Password 값을 받아서 로그인 처리를 하기 위한 Logon 클래스를 생성합니다.
아래와 같이 Logon 클래스를 추가하고, 코딩합니다.
package com.javamodeling.struts2;
import com.opensymphony.xwork2.ActionSupport;
public class Logon extends ActionSupport {
public String execute() throws Exception {
if (isInvalid(getUsername())) return INPUT;
if (isInvalid(getPassword())) return INPUT;
return SUCCESS;
}
private boolean isInvalid(String value) {
return (value == null || value.length() == 0);
}
private String username;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
private String password;
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}
위 Logon class 에서 비즈니스 로직이 수행되는 것은 execute() 메소드입니다. Logon.action 이 호출되면 execute() 메소드가 실행되고 비즈니스 로직이 수행되고, HTML Form 값은 자동으로 Action 클래스의 getter/setter 로 지정된 property 에 저장이 됩니다.
위의 Logon 클래스에서 setUserName() 과 setPassword() 메소드가 HTML Form 의 값을 저장하여 Logon 클래스에 해당 값이 저장됩니다.
5. Selecting Results
Request 에 대한 Action 이 수행된 후, Response 를 처리하기 위해서 Result 가 선택되어집니다. Result 는 간단한 HTML 페이지, JSP 페이지, Freemaker 나 Velocity 같은 Template 엔진, 혹은 PDF 같은 문서나 복잡한 리포트로 Forward 될 수 있습니다. 또한 Action mapping 통하여 여러개의 Result 도 가능합니다. 특정 하나의 Result 로 선택되기 위해서는, Action 클래스에서 Result 에 맞는 결과 값을 리턴해야 합니다.
아래와 같이 struts.xml 에 코드를 추가합니다.
Logon.jsp 에서 username 과 password 를 입력하면 Logon Action 에서 success 값을 리턴합니다. succuess 값은 디폴트 result 값으로써, Menu action 으로 전송됩니다.
만약에 두 값이 입력되지 않으면, Logon Action 은 input 값을 리턴하게 되고, 다시 Logon.jsp 로 Forwarding 됩니다.
일반적으로 Result 의 Type 은 Dispatcher forward 입니다. 이는 특정 JSP 페이지로 forwarding 을 하며, 위에서 설정된 redirect-action 은 client browser 에서 다시 rediect 를 생성하게 하여 Action 을 호출합니다.
Logon Action 이 정상적으로 수행하고 난 후, 다음으로 Forwarding 할 페이지를 아직 결정하지 않았습니다. 그래서 Logon Action 이 정상적으로 수행되고 난 후에 Forwarding 할 Menu.jsp 파일을 아래와 같이 생성하고 코딩합니다.
Menu Action 이 호출되면, Menu.jsp 으로 Forwarding 됩니다. 이렇게 되는 것은 위에서 struts.xml 파일에 * 라는 wildcard 를 설정해 놓았고, Action Name 과 동일한 JSP 파일로 Forwarding 하게 되어 있습니다. 따라서 Logon Action 에서 Menu Action 을 호출하게 되면, Menu.jsp 로 Forwarding 됩니다.
하나의 JSP 페이지로 화면에 보이는 모든 내용을 포함하지는 않습니다. 여러개의 JSP 파일로 나누어서 한 화면을 구성하는게 일반적입니다. 따라서 Struts 2 태그를 사용하여 다른 JSP 파일을 포함하는 것은 아래와 같은 태그를 사용할 수 있습니다.
<%@ taglib prefix="s" uri="/struts-tags" %>
<s:include value="Missing.jsp" />
6. Validating Input
앞서서 Logon Action 에서는 User Name 과 Password 에서 Validation 을 수행하였습니다. 이렇게 간단한 어플리케이션에서는 코드상에서 Validation 을 체크할 수도 있지만, 큰 어플리케이션이나 대용량 어플리케이션을 개발할 경우에는 코드상에서 Validation 을 체크하는 것은 매우 힘듭니다. 또한 유지보수하는데 매우 어려움이 많습니다.
Struts 2 Framework 에서는 Validation Framework 을 제공하여 Input 값에 대한 Validation 을 체크할 수 있습니다.
Validation 은 XML 파일로 Validation 에 대한 내용을 정의할 수 있고, Annotation 으로 Validation 을 정의할 수 있습니다.
XML 파일은 Action Name 과 동일한 이름으로 시작하고, 파일명 뒷 부분에 "-validation.xml" 이라고 파일명을 정하면 됩니다. 이 문서에서 작성하고 있는 Logon Action 에 Validation 을 설정하려면 Logon-validation.xml 로 파일을 생성하면 됩니다.
LOgon Action 클래스가 있는 같은 패키지에 Logon-validation.xml 파일을 생성하고 아래와 같이 코딩합니다.
위와 같이 Validation 을 추가하면, 첫 페이지를 호출할때 Validation 을 수행하게 됩니다. 하지만 첫 페이지는 그냥 입력화면을 처리하고 Validation 을 수행하지 말아야 합니다.
따라서 첫 페이지를 호출할때, Validation 을 수행하지 않게 하기 위해서 Welcome.jsp 와 struts.xml 파일을 아래와 같이 수정합니다.
Logon 화면이 보일때 까지 과정
Logon 페이지에서 Submit 버튼을 클릭할 경우
7. Localizing Output
Validation 체크할 경우, 메시지를 화면에 보여줬습니다. 같은 메시지를 여러 곳에 처리하거나, 각자 다른 언어를 사용할 경우, 해당 언어에 맞는 메시지를 화면에 보여줘야 할 경우가 많이 있습니다.
이럴때 메시지를 리소스 번들(Resource Bundle)에 저장해서 사용하면 매우 편리합니다.
페이지에서 나타내는 메시지와 Validation 에서 처리하는 메시지를 저장하기 위한 Resouce Bundle 을 생성해 보겠습니다.
Struts 2 에서 Resource Bundle 은 Action Name 과 동일하게 주고, 파일 확장자를 .properties 로 주면 됩니다. 따라서Logon Action 에 대한 Resource Bundle 파일명은 Logon.properties 가 됩니다.
파일이 저장되는 위치는 Validation 과 마찬가지로, Action 클래스의 패키지 경로와 동일합니다.
그리고 해당 패키지에서 공통적으로 사용되는 Resource Bundle 을 정의하고 싶으면, package.properties 파일을 만들면 이 package.properties 가 있는 패키지 경로의 모든 클래스에서 사용할 수 있습니다.
우선 Logon Action 과 같은 패키지 경로에 package.properties 파일을 생성하고 아래와 같이 입력합니다.
그리고 위에서 정의한 Resource Bundle 을 사용하도록, Logon.jsp 파일과 Logon-validation.xml 파일을 수정합니다.
한글 메시지를 보이게 하는 것을 살펴보겠습니다. Resource Bundle 을 사용하는데 있어서 한글 메시지를 처리하기 위해서는 한글이 유니코드로 저장이 되어야 합니다.
Logon Action 클래스가 위치한 곳에 Logon.properties 파일을 생성하고 아래와 같이 입력합니다.
//requiredstring = $\{getText(fieldName)} 는 필수입력입니다.
requiredstring = $\{getText(fieldName)} \ub294\u0020\ud544\uc218\uc785\ub825\uc785\ub2c8\ub2e4.
//password = 암호
password = \uc554\ud638
//username = 사용자명
username = \uc0ac\uc6a9\uc790\uba85
정리
Struts 2 Framework 을 사용하여 간단한 어플리케이션을 작성하였습니다. Eclipse 로 쉽게 따라할 수 있도록 이미지를 많이 추가하였으며, 혹시 궁금한 점이 있으시면 아래 게시판에 글을 남겨주시기 바랍니다.
현상 기록
이클립스를 시작하고 톰캣을 통하여 파일을 실행한 후
일정한 시간이 지난 후 사용이 불가능할 정도로 느려지거나 이클립스가 자동으로 종료되는 현상과 같이
한번 씩 아래와 같은 에러 메시지를 출력하였습
에러메시지 기록
an out of memory error has occurred.
consult the "running eclipse" section of the read me file for information on prevention this kind of error in the future.
you are recommended to exit the workbench.
subsequent errors may happen and may terminate the workbench without warning
see the . log file for more details.
do you want to exit the workbench?
해결방법 기록
이클립스가 설치되어 있는 폴더의 구성 설정 파일을 메모장을 이용하여 메모리 설정을 변경하여 해결

파일을 열어보면
| -showsplash org.eclipse.platform --launcher.XXMaxPermSize 256M → 이것이 256이면 시작시 에러발생;;이유모르겠음. -vmargs |
와 같이 기록 되어 있으며 이것을 아래와 같이 변경을 하였음
| -showsplash org.eclipse.platform -vmargs 메소드 이름등이 저장되는 메모리 영역의 최대 크기를 지정합니다. -Dosgi.requiredJavaVersion=1.5 |
참고한 사이트
http://blog.naver.com/xicnt?Redirect=Log&logNo=20041603687
추가 기록
현재 총 사용가능한 메모리가 2G 임에 무작정 메모리문제로 이클립스가 다운되니 메모리 할당을 많이 많이 하였습니다.
그래도 문제는 해결이 되지 않았으며 저의 경우 우연히 메모리 할당을 낮게 함으로써 문제가 해결되었습니다.
저에게 필요했던 PermSize 메모리 는 256m 수준
저에게 필요했던 일반적인 메모리 는 128m 수준
하지만 반대로 일반적인 메모리 영역도 무작정 많이 할당하다보니(512씩 줘도 1G 밖에 안되고 나는 메모리 2G 이니까 하는 생각에) 제가 사용할수 있는 메모리를 초과하게 되었습니다.
[출처] 이클립스 사용 에러|작성자 잔잔바람
유닉스 콘솔에서 ftp 명령어 mput 사용시 파일 하나 전송할때마나 y/n를 물어 보는것을
없애는 방법은. prompt 키워드로 대화식 모드를 off 로 해야 함.
ftp> prompt
하면됨. 한번 더하면 원래 대로 돌아옴.
ftp> binary
바이너리 모드로 전송됨.
ftp> mput *
모든 파일이 전송됨. 간혹 mput *.* 하면 전송안되는 파일이 있음. ㅋㅋ
확장자가 없는 파일이 있기 때문에....
PS.
-
*파일 보내기, 가져오기
mget * : 디렉토리를 제외한 나머지파일을 모두 가져온다.
mget -R BACKUP : BACKUP이란 폴더 안에 존재하는 모든내용을 가져온다.
mget -R * : 역시 하위폴더까지 모두 가져온다.
mget *.html : 하위의 모든.html을 가지고 올경우
get -R *.html : 하위 디렉토리 하위의 것까지 가지고 올경우
- mget , mput
#> mget * -> 여러파일 받을때
#> by or bye or quit ->나갈때
FTP 명령어
리눅스에서 기본지원되는 FTP 명령에 대한것을 정리해보았습니다.
1.원격서버 열기
=> $ftp 210.xxx.xxx.xxx
Connected to 210.xxx.xxx.xxx.
220 web17 FTP server ready.
Name :아이디입력
331 Password required for w3invest.
Password:패스워드입력
230 User chchu logged in.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp>
2.디렉토리이동
=> ftp>cd /html/upload
3.현재 디렉토리 확인
=> ftp>pwd
4.Local 디렉토리이동
=> ftp>lcd /bin
=> Local directory now /bin
5.파일 전송 타입 설정
=> ftp>ascii
=> 200 Type set to A.
=> ftp>binary
=> 200 Type set to I.
6.파일 Download
=> ftp>binary
=> ftp>ls
=> ftp>get thinkinjava.pdf
=> local: R387.PDF remote: R387.PDF
=> 200 PORT command successful.
=> 150 Opening BINARY mode data connection for R387.PDF .
=> 226 Transfer complete.
=> 19041 bytes received in 3.99 secs
7.파일 다운로드
=> ftp>mget *.PDF
8.파일 전송상태 표시하기
=> ftp>hash
=> Hash mark printing on .
=> ftp>get R389.PDF
=> local: R389.PDF remote: R389.PDF
=> 200 PORT command successful.
=> 150 Opening BINARY mode data connection for R389.PDF .
=> ##########################################
=> 226 Transfer complete.
=> 44028 bytes received in 12.1 secs
9.종료 하기
=> ftp>bye
=> ftp>exit
10.도움말
=> ftp>help
원본 위치 <>
기타 다른 것
1. 유저가 루트로 FTP 로그인할 수 있게 하는 방법
# 텔넷의 root 로그인 방법이 설정 되고 난 이후
$ vi /etc/ftpusers
#root
2. FTP 포트번호 변경하기
# 디폴트 21번을 6번으로 변경한 예
$ vi /etc/services
ftp 6/tcp
3. FTP 사용법
# ftp 접속지 주소 포트번호
$ ftp 192.168.1.39 6
Name:
Password:
ftp> help/ ftp> user # 로그인 실패시 재 로그인
ftp> ls/!dir # 서버명령/클라이언트명령 수행
ftp> cd/lcd # 서버/클라이언트 디렉토리 이동.
ftp> delete/rename # 파일 지우기/이름바꾸기
ftp> mkdir/rmdir # 디렉토리 생성/삭제
ftp> get/put # 파일 전송
ftp> mget/mput # 여러개 파일 가져올 때
ftp> binary/ascii # 전송파일타입을 이진/아스키 파일로 지정한다.
ftp> type binary/ascii # 전송파일타입을 이진/아스키 파일로 지정한다.
ftp> hash # 받는 파일의 양을 화면에 표시 합니다.
ftp> prompt # mget/mput 할 때 y/n 질문을 하지 않게 한다.
ftp> bye/quit # 끝내기
ftp> open/close hostname # 원격 호스트에 접속/단절 한다.
ftp> status # ascii/binary, glob on/off 등 현재 ftp 세션의 접속 파라미터를 출력한다.
ftp> pwd # 현재의 절대 경로
ftp> verbose on # 전송중에 발생하는 정보를 화면에 보여준다.
주위: 윈도우 DOS 창에서의 FTP 사용 - 포트번호 지정이 않되고, 파일이 잘 전송이 않된다.
WS-FTP 프로그램 - 포트번호 변경이 안된다.
권장 FTP 편집기 - 울트라에디트
권장 FTP 프로그램 - Cute FTP, Leech FTP
4. 활용팁
- mget mput명령시에 파일 하나마다 y를 누르는 불편 없애기.
ftp> prompt 하고
ftp> mget 하면 된다.
또는, 접속시에 ftp -i xxx.xxx.xxx.xxx 하면 된다.
FTP 명령어-
ascii : 전송모드를 ASCII모드로 설정한다.
binary : 전송모드를 BINARY모드로 설정한다.
bell : 명령어 완료시에 벨소리를 나게한다.
bye : ftp접속을 종료하고 빠져나간다.
cd : remote시스템의 디렉토리를 변경한다.
cdup : remote시스템에서 한단계 상위디렉토리로 이동한다.
chmod : remote시스템의 파일퍼미션을 변경한다.
close : ftp접속을 종료한다.
delete : remote시스템의 파일을 삭제한다.
dir : remote시스템의 디렉토리 내용을 디스플레이한다.
disconnect : ftp접속을 종료한다.
exit : ftp접속을 종료하고 빠져나간다.
get : 지정된 파일하나를 가져온다.
hash : 파일전송 도중에 #표시를 하여 전송중임을 나타낸다.
help : ftp명령어 도움말을 볼 수 있다.
lcd : local시스템의 디렉토리를 변경한다.
ls : remote시스템의 디렉토리 내용을 디스플레이한다.
mdelete : 여러개의 파일을 한꺼번에 지울 때 사용한다.
mget : 여러개의 파일을 한꺼번에 가져오려할 때 사용한다.
mput : 한꺼번에 여러개의 파일을 remote시스템에 올린다.
open : ftp접속을 시도한다.
prompt : 파일전송시에 확인과정을 거친다. on/off 토글
put : 하나의 파일을 remote시스템에 올린다.
pwd : remote시스템의 현재 작업디렉토리를 표시한다.
quit : ftp접속을 종료하고 빠져나간다.
rstatus : remote시스템의 상황을 표시한다.
rename : remote시스템의 파일명을 바꾼다.
rmdir : remote시스템의 디렉토리을 삭제한다.
size :remote시스템에 있는 파일의 크기를 byte단위로 표시한다.
status : 현재 연결된 ftp세션모드에 대한 설정을 보여준다.
type : 전송모드를 설정한다.
HashMap
HashMap은 키나 값에 Null을 허용 합니다.
HashMap 출력방법은 다음 한가지 이네요. (Enumeration 지원 안함)
HashMap hashmap = new HashMap();
hashmap.put("jakarta", "project");
hashmap.put("apache", "tomcat");
Set set = hashmap.entrySet();
Iterator keys = set.iterator();
while (keys.hasNext()) {
key = (String)keys.next();
System.out.println(hashmap.get(key));
}
또한 Hashtable은 thread safe 한 객체이지만 HashMap은 그렇지 못해 unsynchronized 합니다.
이말은 즉 멀티 쓰레드 환경이 아니면 HashMap을 쓰면 속도가 빠르다는 말입니다.
굳이 동기화 하자면 다음과 같이 사용해야 겠지요
Map m = Collections.synchronizedMap(new HashMap(...));
간단히 정리하자면
HashMap이 HashTable에 비해 좀더 실용적으로 변한 형태라고 보면 되겠네요 ^^
일반적으로 쓴다면 HashMap을 사용하세요
HashMap 이나 Hashtable 이나 둘다 Map 인터페이스를 implements 하고있지만 프로그래밍 환경에 따라서 적절한 놈으로 골라써야 합니다.
java API 문서에 보면
The HashMap class is roughly equivalent to Hashtable, except that it is unsynchronized and permits nulls.
"간략히 말해서 HashMap 은 Hashtable과 같다, 다만 HashMap 이 unsynchronized 하고 null 값을 허용할 뿐이다."
그러면 Hashtable 에는 null 값이 들어갈 수 없다는건가? 이건 잘 모르겠지만 Hashtable 만들어놓고 null 키값과 null value 를 함 넣어보시면 확인하실 수 있을 듯합니다...
중요한 건 HashMap은 멀티쓰레드 환경에서 사용하면 안된다는 겁니다.
여러개의 쓰레드가 동시에 HashMap 을 건드려서 key, value 를 써넣게 되면 문제가 발생할 수 있다, 뭐 이런것 같습니다. 멀티쓰레드 프로그래밍 환경에서는 HashMap 을 쓰면 안되고 Hashtable 을 써야 한다는 거죠...
단일 쓰레드 환경에서 Hashtable 을 쓰더라도 별 문제는 없는데, HashMap보다는 성능이 저하될 수 있습니다.
HashMap : http://sunny.sarang.net/api/java/util/HashMap.html
실예)
import java.util.*;
public class HashMapTest {
public static void main(String arg[]) {
HashMap hm = new HashMap();
hm.put("1", "one");
hm.put("2", "two");
hm.put("3", "three");
hm.put("4", "four");
//TreeMap code = new TreeMap(hm);//sorting이 필요하시면 추가하세요.변수명 바꾸시구요
Iterator ir = hm.keySet().iterator();//HashMap의 모든 key 값을 Iterator 객체에 담는다.
while(ir.hasNext()){
String key = (String)ir.next();//하나씩 key값을 가져온다 여기서 특정 key 값과 비교하실려면
//if(key.equals("특정key값"){}//이렇게 비교하셔서 매칭 되는것만 출력하시든지 처리하시면 될것 같습니다.
String value = (String) hm.get(key);//그키값으로 HashMap의 값을 가져온다.
System.out.println("key = "+key+", value = "+value);
//System.out.println("");
//System.out.println(ir);
} /// while
} /// main
} /// class
HashTable
Hashtable 은 키나 값에 Null을 허용하지 않습니다.
또한 Object에 정의된 hashCode()와 equals()메소드를 재정의하는 객체들만 저장할 수 있습니다.
다행히도 자바 내장 클래스들은 대부분 hashCode()구현되어 있다는 것을 아실겁니다.
특히 String 타입이 hashCode(), equals()메소드 두개 모두 구현되어 있지요.
Hashtable은 Map 클래스와 마찬가지로 반복자(interator)를 직접제공 하지 않습니다
다음 두가지 방식으로 HashTable 내용을 출력합니다.
Hashtable hashtable = new Hashtable();
hashtable.put("jakarta", "project");
hashtable.put("apache", "tomcat");
Enumertaion keys = hashtable.keys();
while(keys.hasMoreElements()) {
key = (String)keys.nextElement();
System.out.println(hashtable.get(key));
}
혹은
Set set = hashtable.keySet();
Iterator keys = set.interator();
while(keys.hasNext()) {
key = (String)keys.next();
System.out.println(hashtable.get(key));
}
HashTable은 Map 인테페이스로부터 확장한 클래스이다.
Vector와의 차이점은 특정 킷값을 갖고 데이터를 검색할 수 있다는 것이다.
HashTable를 생성할 때 load factor를 정할 수 있는데 이는 메모리를 절약할것인가, 처리속도를 높일것인가를 결정하는 float형태의 값이다.
load factor 의 범위 : 0.0 ~ 1.0
0.0 : 처리속도가 가장 빠름. 메모리 소모 가장 많음.
1.0 : 처리속도 느림. 메모리 절약
주요 생성자
HashTable() 기본 저장공간을 11개와 load factor는 0.75를 갖는다.
HashTable(int Capacity)
초기공간을 지정하여 생성. load factor는 0.75
HashTable(int Capacity, float loadFactor)
초기 공간과 load factor를 지정하여 테이블 생성
| HashTable() | 기본 저장공간을 11개와 load factor는 0.75를 갖는다. |
|
HashTable(int Capacity) |
초기공간을 지정하여 생성. load factor는 0.75 |
|
HashTable(int Capacity, float loadFactor) |
초기 공간과 load factor를 지정하여 테이블 생성 |
주요 메소드
boolean containsKey(Object key)
해당 key값이 있는지 검색한다.
boolean containsValue(Obejct value) 해당 value 값이 있는지 검색한다.
void put(Object key, Object value) 해시테이블에 값을 넣는다. 만약 킷값이 동일하면 기본의 데이터가 대치된다.
int size() 해시 테이블에 있는 실제 요소의 갯수를 반환한다.
Object get(Object key) 킷값에 해당하는 값을 가져온다.
void clear() 모든 킷값과 value를 지운다.
|
boolean containsKey(Object key) |
해당 key값이 있는지 검색한다. |
| boolean containsValue(Obejct value) | 해당 value 값이 있는지 검색한다. |
| void put(Object key, Object value) | 해시테이블에 값을 넣는다. 만약 킷값이 동일하면 기본의 데이터가 대치된다. |
| int size() | 해시 테이블에 있는 실제 요소의 갯수를 반환한다. |
| Object get(Object key) | 킷값에 해당하는 값을 가져온다. |
| void clear() | 모든 킷값과 value를 지운다. |
[실예]
import java.util.*;
class HashtableEx
{
Hashtable ht = new Hashtable(10);
public HashtableEx()
{
ht.put("1", "one");
ht.put("2", "two");
ht.put("3", "thee");
ht.put("4", "four");
ht.put("5", "five");
}
public String get(String s)
{
String result = (String)ht.get(s);
return result;
}
public int size()
{
return ht.size();
}
public static void main(String[] args)
{
HashtableEx h = new HashtableEx();
System.out.println(h.get("1"));
System.out.println(h.size());
}
}
/********** 각 경우별 드라이버 연동하기 **************/
** Access **
연결 URL : jdbc:odbc:설정한 odbc명
드라이버 클래스 : sun.jdbc.odbc.JdbcOdbcDriver
mysql은 JConnector 3.0 부터는 com.mysql.jdbc.Driver
연결 URL 은 jdbc:mysql://localhost/dbname?Unicode=true&characterEncoding=EUC_KR
같이 인코딩 타입을 직접 줌으로써 한글 변환문제에 좀더 쉽게 해결할 수 있음.
** Connected To IBM AS/400 **
Class.forName("com.ibm.as400.access.AS400JDBCDriver");
com = Driver.Manager.getConnection("jdbc:as400://10.20.30.40/testlib;user=user;password=pass");
** Connected To Unisql **
Class.forName("unisql.jdbc.driver.UniSQLDriver");
con = Driver.Manager.getConnection("jdbc:unisql:10.20.30.40:43300:demodb:::", "user","pass");
** Connected To Jdbc-Odbc Type - 1 Driver **
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
// con = DriverManager.getConnection("Jdbc:Odbc:dsnname","userid","password");
con = DriverManager.getConnection("jdbc:odbc:Driver={SQL Server};Server=servername;Database=pubs","userid","password");
** Connected To Ms-Access JDBC ODBC Driver **
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
con = DriverManager.getConnection("Jdbc:Odbc:dsnname","","");
// con = DriverManager.getConnection("jdbc:odbc:Driver={MicroSoft Access Driver (*.mdb)};DBQ=G:/admin.mdb","","");
** Connected To Ms-Access Type-3 Driver **
Class.forName ("acs.jdbc.Driver");
String url = "jdbc:atinav:servername:5000:C:\\admin.mdb";
String username="Admin";
String password="";
Connection con = DriverManager.getConnection(url,username,password);
** Connected To Microsoft SQL **
Class.forName("com.microsoft.jdbc.sqlserver.SQLServerDriver");
con = DriverManager.getConnection("jdbc:microsoft:sqlserver://servername:1433","userid","password");
** Connected To Merant. **
Class.forName("com.merant.datadirect.jdbc.sqlserver.SQLServerDriver");
con = DriverManager.getConnection("jdbc:merant:sqlserver://servername:1433;User=userid;Password=password");
** Connected To Atinav SqlServer. **
Class.forName ("net.avenir.jdbc2.Driver");
con= DriverManager.getConnection("jdbc:AvenirDriver://servername:1433/pubs","userid","password");
**Connected To J-Turbo. **
String server="servername";
String database="pubs";
String user="userid";
String password="password";
Class.forName("com.ashna.jturbo.driver.Driver");
con= DriverManager.getConnection("jdbc:JTurbo://"+server+"/"+database,user,password);
** Connected To jk Jdbc Driver. **
String url= "jdbc:jk:server@pubs:1433";
Properties prop = new Properties();
prop.put("user","userid");//Set the user name
prop.put("password","password");//Set the password
Class.forName ("com.jk.jdbc.Driver").newInstance();
con = DriverManager.getConnection (url, prop);*/
** Connected To jNetDirect Type - 4 Driver **
String sConnect = "jdbc:JSQLConnect://127.0.0.1/database=pubs&user=userid&password=password";
Class.forName ("com.jnetdirect.jsql.JSQLDriver").newInstance();
Connection con= DriverManager.getConnection(sConnect);
** Connected To AvenirDriver Type - 4 Driver **
// String url= "jdbc: AvenirDriver: //servername:1433/pubs";
// java.util.Properties prop = new java.util.Properties ();
// prop.put("user","userid");
// prop.put("password","password");
Class.forName ("net.avenir.jdbc2.Driver");
System.out.println(" Connected To AvenirDriver Type - 4 Driver");
con= DriverManager.getConnection("jdbc:AvenirDriver://servername:1433/pubs","userid","password");
** Connected To iNet Sprinta2000 Type - 4 Driver **
String url="jdbc:inetdae7:servername:1433";
String login="userid";
String password="password";
Class.forName("com.inet.tds.TdsDriver");
System.out.println(" Connected To iNet Sprinta2000 Type - 4 Driver");
con=DriverManager.getConnection(url,login,password);
** Connected To iNet Opta2000 Type - 4 Driver **
String url="jdbc:inetdae7:servername:1433";
String login="sagar";
String password="sagar";
Class.forName("com.inet.tds.TdsDriver").newInstance();
System.out.println(" Connected To iNet Opta2000 Type - 4 Driver");
con=DriverManager.getConnection(url,login,password);